Pandas入门3(dtype+fillna+replace+rename+concat+join)
本文共 1985 字,大约阅读时间需要 6 分钟。
文章目录
上一篇:
5. dtype 数据类型
print(wine_rev.price.dtype),float64wine_rev.dtypes,整张表,需要加复数s!!!
country objectdescription objectdesignation objectpoints int64price float64province objectregion_1 objectregion_2 objecttaster_name objecttaster_twitter_handle objecttitle objectvariety objectwinery objectcritic objecttest_id int32dtype: object
- 字符串的数据类型为
object astype(),可以进行类型转换wine_rev.points.astype('float64')
0 87.01 87.02 87.03 87.04 87.0 ... 129966 90.0129967 90.0129968 90.0129969 90.0129970 90.0Name: points, Length: 129971, dtype: float64
wine_rev.index.dtype,索引的类型是dtype('int64')
6. Missing data 缺失值
6.1 查找缺失值 pd.isnull(),pd.notnull()
缺少值的条目将被赋予值NaN,是Not a Number的缩写。这些NaN值始终为float64 dtype。
NaN条目,可以使用pd.isnull(),pd.notnull() wine_rev[pd.isnull(wine_rev.country)]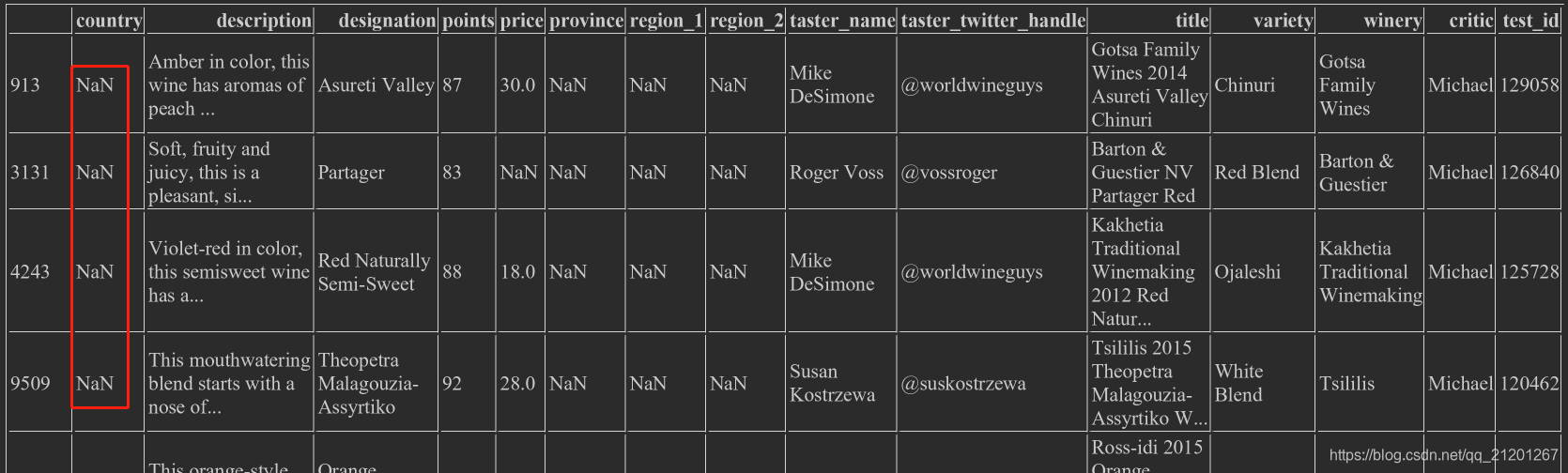
6.2 填补缺失值 fillna(),replace()
wine_rev.region_2.fillna('Unknown'),原始数据不改变- 还可以把缺失值填成之前出现的第一个非空值,称为回填策略
wine_rev.taster_twitter_handle.replace("@kerinokeefe", "@kerino"),把前者替换成后者
7. Renaming and Combining 重命名、合并
7.1 Renaming 重命名
- 把名字改成我们喜欢的,更合适的,
rename(),可以把索引名、列名更改 wine_rev.rename(columns={'points':'score'})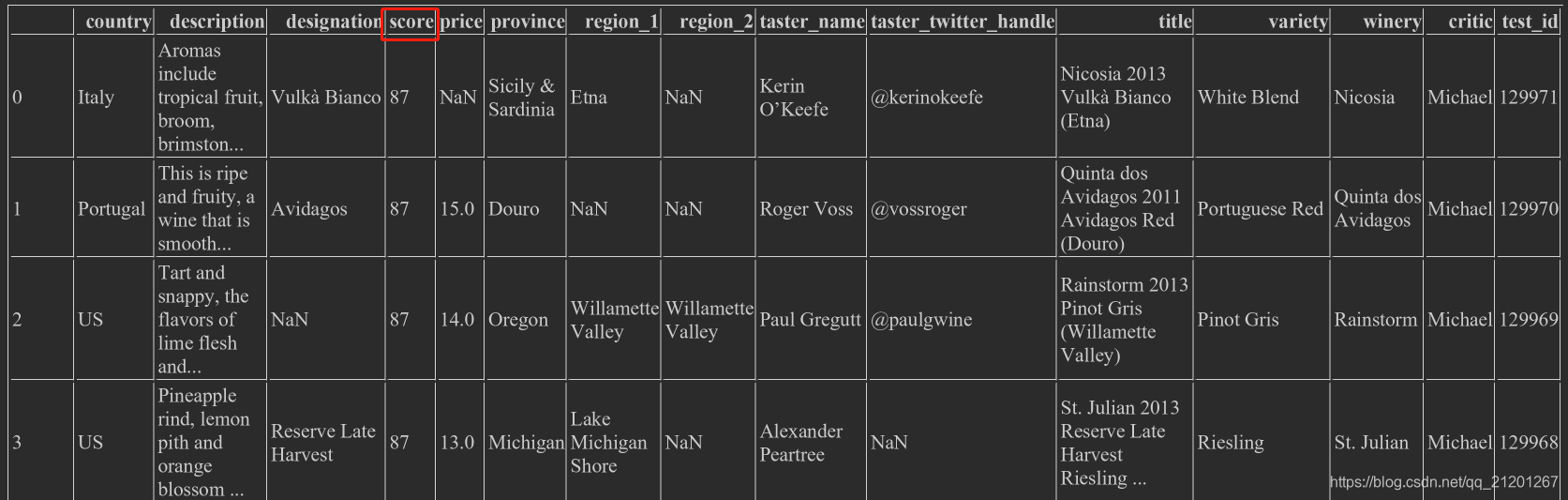
- 更改
index,wine_rev.rename(index={0:'michael',1:'ming'}),index={字典}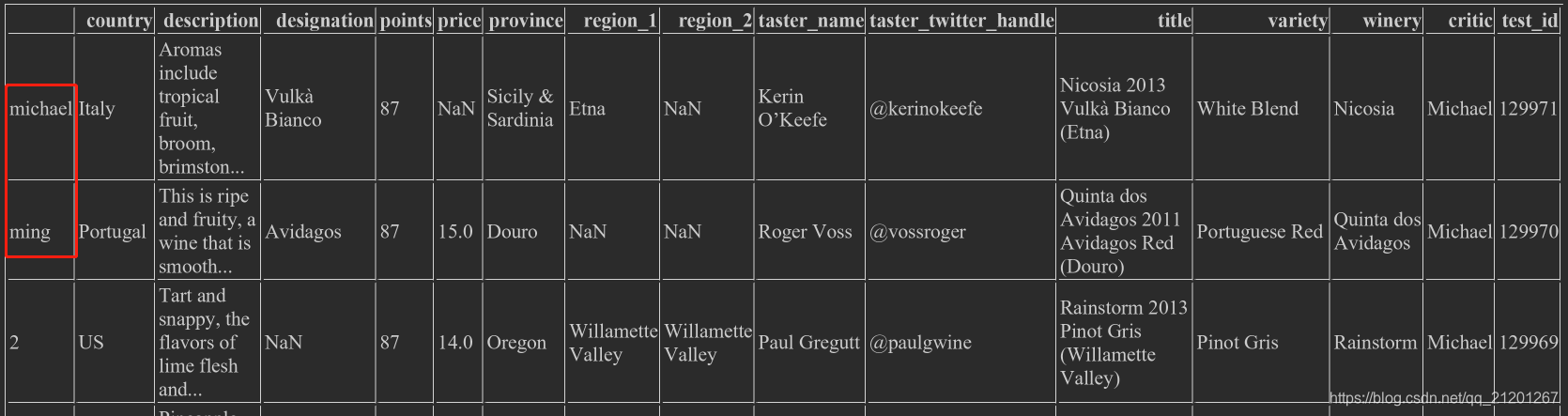
rename_axis(),可以更改行索引、列索引名称wine_rev.rename_axis("酒",axis='rows').rename_axis('特征',axis='columns')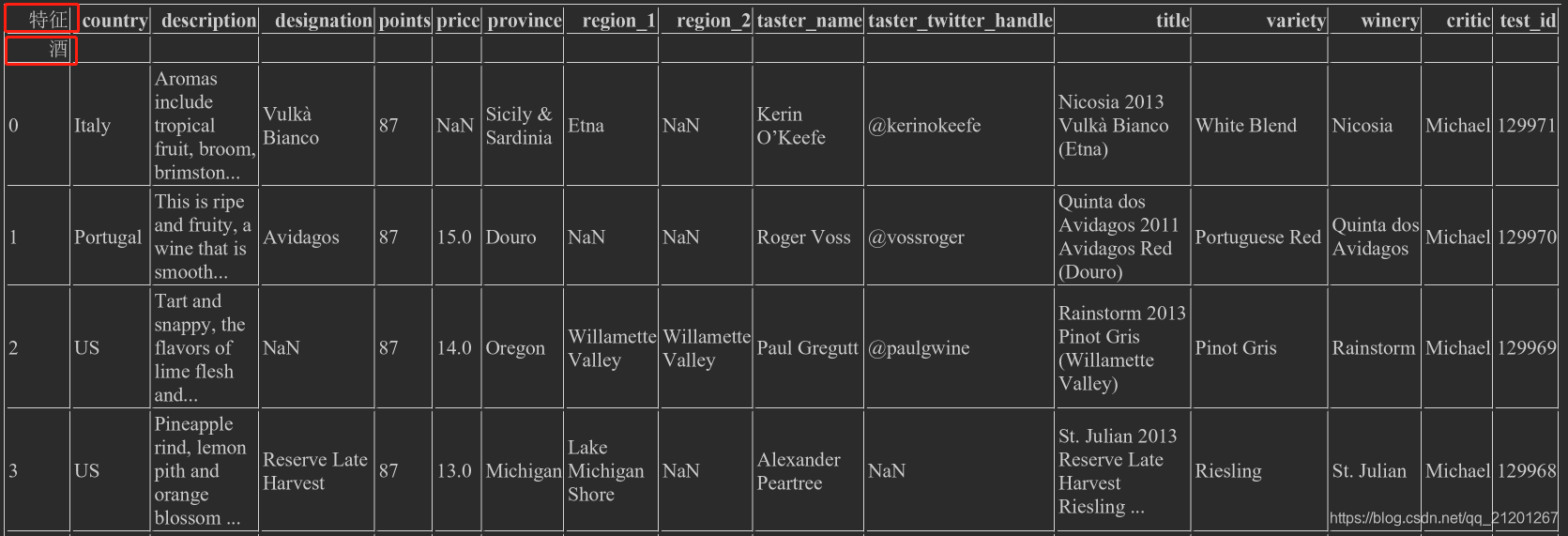
7.2 Combining 合并数据
concat(),join() 和 merge()
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")pd.concat([canadian_youtube, british_youtube]) left = canadian_youtube.set_index(['title', 'trending_date'])right = british_youtube.set_index(['title', 'trending_date'])left.join(right, lsuffix='_CAN', rsuffix='_UK')
完成了课程+练习,获得,继续加油!🚀🚀🚀
上一篇:
转载地址:http://juhtf.baihongyu.com/
你可能感兴趣的文章
EFI Shell 命令参考
查看>>
HP-UX oracle RAC 双机实践
查看>>
解决SHELL脚本中的export无法生效的问题【转】
查看>>
linux中的sh脚本语法【转】
查看>>
区别数据结构中的堆栈与内存中的堆栈的个人总结【转】
查看>>
c++中冒号(:)和双冒号(::)的用法【转】
查看>>
python中各种下划线的含义
查看>>
《计算机视觉-一种现代方法(第2版)》读书笔记三:早期视觉(一幅图像)
查看>>
《计算机视觉-一种现代方法(第2版)》读书笔记六:应用之图像搜索和检索
查看>>
如何撰写高水平的学术论文
查看>>
谭浩强《C++面向对象程序设计》知识点总结
查看>>
分享一个关于介绍TextCNN和TextRNN的文章
查看>>
关于CNN中感受野的理解和计算方法
查看>>
java基础----RandomAccessFile
查看>>
__attribute__((packed))
查看>>
Android深入浅出之Binder机制
查看>>
linux查看硬件信息
查看>>
linux支持大于4G内存
查看>>
WM_GETINFO相关
查看>>
填入空隙(setbkcolor,setbkmode)
查看>>